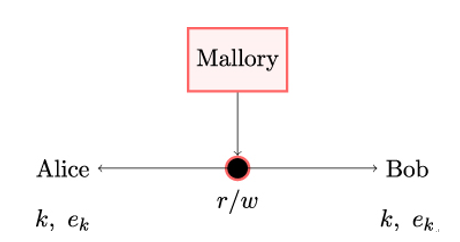
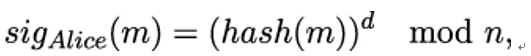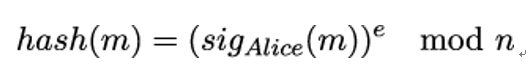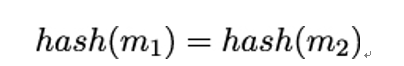10.2.6 X.509 trust model
Generally speaking, there are three steps in verifying a certificate:
- Verify that the certificate has not been revoked
- Verify that the certificate is valid (for instance, verify the certificate’s extensions and its validity period)
- Verify the signature of the CA over the certificate
As discussed earlier, the first step consists of either consulting a CRL or an OCSP server. But to verify the signature over a certificate (or a CRL or an OCSP response), we need an authentic copy of the CA’s public key – in other words, we need another certificate, in which the original CA is the subject. In X.509, these CA certificates are issued by a higher-order CA, which in turn has a certificate from an even higher-order CA, so that a hierarchical tree structure emerges with a Root CA at the top, which certifies itself (see Figure 10.4).
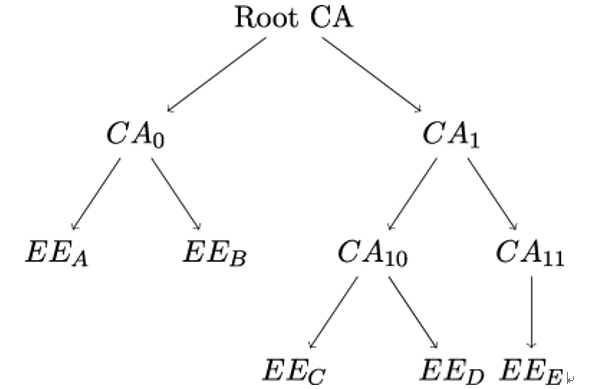
Figure 10.4: X.509 hierarchical trust model. An arrow from X to Y means that X certifies Y . EE stands for End Entity
The Path Length Constraint within the Basic Constraints extension field limits the number of CA certificates that may follow a CA certificate down the tree until the EE certificate under consideration is reached. For CA0 in Figure 10.4, for example, the path length constraint could be set to 0, whereas for CA1, the path length constraint should be at least 1, lest verification of the end entity certificates for C,D, and E fails.
In practice, a CA is rarely certified by another, independent CA. Rather, there are instances within the same company that act as root CAs for their own intermediate CA instances. From a security perspective, this is equivalent to a CA self-signing its own public key. This means that, in most cases, the relying parties cannot transfer the question of whether to trust a particular CA to some independent higher-order instance, but must base their trust decisions entirely on the publicly available information about a CA, for example, the CPS. Although modern browsers contain lists of trusted CAs, it is not entirely clear how these lists come about, and they should be no substitute for making your own decisions.