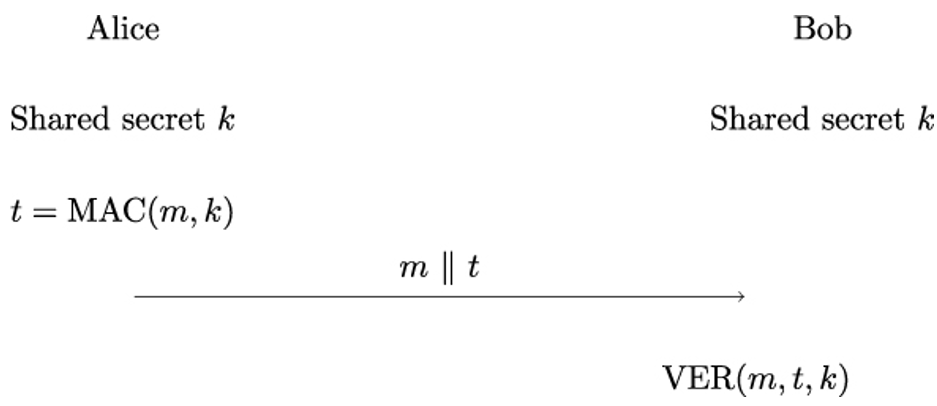
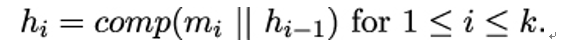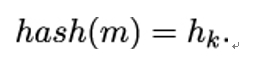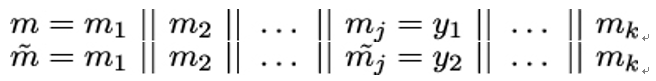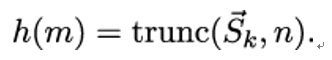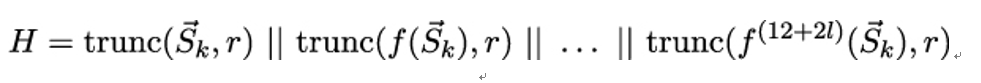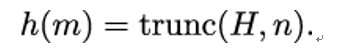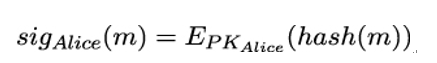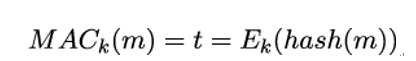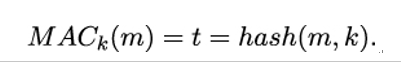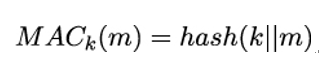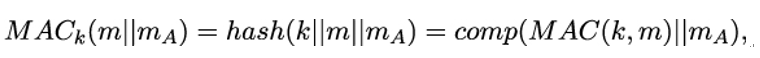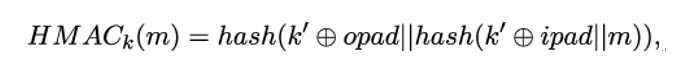11.3.2 Candidate one-way functions
With the current knowledge in complexity theory, mathematicians do not know how to unconditionally prove the existence of one-way functions. As a result, their existence can only be assumed. There are, however, good reasons to make this assumption: there exists a number of very natural computational problems that were the subject of intense mathematical research for decades, sometimes even centuries, yet no one was able to come up with a polynomial-time algorithm that can solve these problems.
According to the fundamental theorem of arithmetic, every positive integer can be expressed as a product of prime numbers, the numbers being referred to as prime factors of the original number [74]. One of the best known computational problems that is believed to be a one-way function is prime factorization: given a large integer, find its prime factors.
The first table of prime factors of integers was created by the Greek mathematician Eratosthenes more than 2,500 years ago. The last factor table for numbers up to 10,017,000 was published by the American mathematician Derrick Norman Lehmer in 1909 [178].
Trial division was first described in 1202 by Leonardo of Pisa, also known as Fibonacci, in his manuscript on arithmetic Liber Abaci. French mathematician Pierre de Fermat proposed a method based on a difference of squares, today known as Fermat’s factorization method, in the 17th century. A similar integer factorization method was described by the 14th century Indian mathematician Narayana Pandita. The 18th century Swiss mathematician Leonhard Euler proposed a method for factoring integers by writing them as a sum of two square numbers in two different ways.
Starting from the 1970s, a number of so-called algebraic-group factorization algorithms were introduced that work in an algebraic group. As an example, the British mathematician John Pollard introduced two new factoring algorithms called the p− 1 algorithm and the rho algorithm in 1974 and 1975, respectively. The Canadian mathematician Hugh Williams proposed the Williams’ p + 1 algorithm in 1982.
In 1985, the Dutch mathematician Hendrik Lenstra published the elliptic curve method, currently the best known integer factorization method among the algorithms whose complexity depends on the size of the factor rather than the size of the number to be factored [204].
Moreover, a number of so-called general-purpose integer factorization methods whose running time depends on the size of the number to be factored have been proposed over time. Examples of such algorithms are the Quadratic Sieve introduced in 1981 by the American mathematician Carl Pomerance, which was the most effective general-purpose algorithm in the 1980s and early 1990s, and the General Number Field Sieve method, the fastest currently known algorithm for factoring large integers [39].
Yet, except for the quantum computer algorithm proposed in 1994 by the American mathematician Peter Shor, none of the above algorithms can factor integers in polynomial time. As a result, mathematicians assume that prime factorization is indeed a one-way function, at least for classical computers. Shor’s algorithm, on the other hand, requires a sufficiently large quantum computer with advanced error correction capabilities to keep the qubits stable during the entire computation, a technical challenge for which no solutions are known as of today.
Another example of a function believed to be one-way is a family of permutations based on the discrete logarithm problem. Recall that the discrete logarithm problem involves determining the integer exponent x given a number of the form gx where g is a generator of a cyclic group. The problem is believed to be computationally intractable, that is, no algorithms are known that can solve this problem in polynomial time.
The conjectured one-way family of permutations consists of the following:
- An algorithm to generate an n-bit prime p and an element g ∈ {2,…,p − 1}
- An algorithm to generate a random integer x in the range {1,…,p−1}
- The function fp,g(x) = gx (mod p)
Function fp,g(x) is easy to compute, for example, using the square-and-multiply algorithm. Inverting fp,g(x), on the other hand, is believed to be computationally hard because inverting modular exponentiation is equivalent to solving the discrete logarithm problem for which no polynomial-time algorithms are known to date, as discussed in Chapter 7, Public-Key Cryptography.