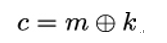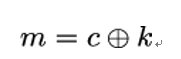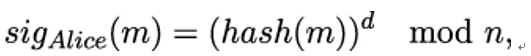11.7 Hash functions in TLS 1.3
We’ll now take a look at how hash functions are negotiated within the TLS handshake and how they are subsequently used in the handshake.
11.7.1 Hash functions in ClientHello
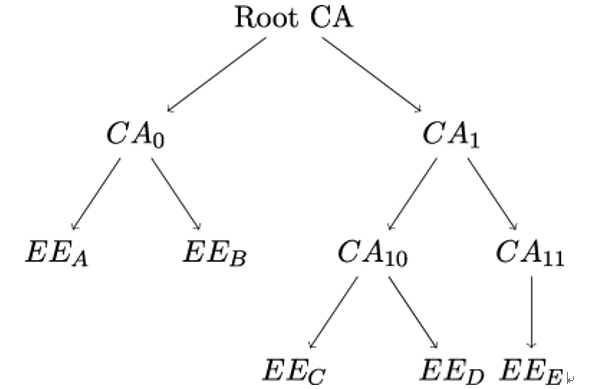
Recall that Alice and Rob use the TLS handshake protocol to negotiate the security parameters for their connection. They do it using TLS handshake messages shown in Listing 11.3. Once assembled by the TLS endpoint – that is, server Alice or client Bob – these messages are passed to the TLS record layer where they are embedded into one or more TLSPlaintext or TLSCiphertext data structures. The data structures are then transmitted according to the current state of the TLS connection.
Listing 11.3: TLS 1.3 handshake messages
enum {
client_hello(1),
server_hello(2),
new_session_ticket(4),
end_of_early_data(5),
encrypted_extensions(8),
certificate(11),
certificate_request(13),
certificate_verify(15),
finished(20),
key_update(24),
message_hash(254),
(255)
} HandshakeType;
One of the most important TLS handshake messages is ClientHello since this message starts a TLS session between client Bob and server Alice. The structure of the ClientHello message is shown in Listing 11.4. The cipher˙suites field in ClientHello carries a list of symmetric key algorithms supported by client Bob, specifically the encryption algorithm protecting the TLS record layer and the hash function used with the HMAC-based key derivation function HKDF.
Listing 11.4: TLS 1.3 ClientHello message
struct {
ProtocolVersion legacy_version = 0x0303; /* TLS v1.2 */
Random random;
opaque legacy_session_id<0..32>;
CipherSuite cipher_suites<2..2^16-2>;
opaque legacy_compression_methods<1..2^8-1>;
Extension extensions<8..2^16-1>;
} ClientHello;
11.7.2 Hash Functions in TLS 1.3 signature schemes
Recall that server Alice and client Bob also agree upon the signature scheme they will use during the TLS handshake. The SignatureScheme field indicates the signature algorithm with the corresponding hash function. The following code shows digital signature schemes supported in TLS 1.3:
enum {
/* RSASSA-PKCS1-v1_5 algorithms */
rsa_pkcs1_sha256(0x0401),
rsa_pkcs1_sha384(0x0501),
rsa_pkcs1_sha512(0x0601),
/* ECDSA algorithms */
ecdsa_secp256r1_sha256(0x0403),
ecdsa_secp384r1_sha384(0x0503),
ecdsa_secp521r1_sha512(0x0603),
/* RSASSA-PSS algorithms with public key OID rsaEncryption */
rsa_pss_rsae_sha256(0x0804),
rsa_pss_rsae_sha384(0x0805),
rsa_pss_rsae_sha512(0x0806),
/* EdDSA algorithms */
ed25519(0x0807),
ed448(0x0808),
/* RSASSA-PSS algorithms with public key OID RSASSA-PSS */
rsa_pss_pss_sha256(0x0809),
rsa_pss_pss_sha384(0x080a),
rsa_pss_pss_sha512(0x080b),
— snip —
} SignatureScheme;
We’ll now discuss the SHA family of hash functions in detail.
SHA-1
SHA-1 is a hash algorithm that was in use from 1995 as part of the FIPS standard 180-1, but has been deprecated by NIST, BSI, and other agencies due to severe security issues with regard to its collision resistance. In 2005, a team of Chinese researchers published the first cryptanalytic attacks against the SHA-1 algorithm. These theoretical attacks allowed the researchers to find collisions with much less work than with a brute-force attack. Following further improvements in these attacks, NIST deprecated SHA-1 in 2011 and disallowed using it for digital signatures in 2013.
In 2017, a team of researchers from the CWI Institute in Amsterdam and Google published Shattered, the first practical attack on SHA-1, by crafting two different PDF files having an identical SHA-1 signature. You can test the attack yourself at https://shattered.io/.
Finally, in 2020, two French researchers published the first practical chosen-prefix collision attack against SHA-1. Using the attack, Mallory can build colliding messages with two arbitrary prefixes. This is much more threatening for cryptographic protocols, and the researchers have demonstrated their work by mounting a PGP/GnuPG impersonation attack. Moreover, the cost of computing such chosen-prefix collisions has been significantly reduced over time and is now considered to be within the reach of attackers with computing resources similar to those of academic researchers [64].
While SHA-1 must not be used as a secure cryptographic hash function, it may still be used in other cryptographic applications [64]. As an example, based on what is known today, SHA-1 can be used for HMAC because the HMAC construction does not require collision resistance. Nevertheless, authorities recommend replacing SHA-1 with a hash function from the SHA-2 or SHA-3 family as an additional security measure [64].