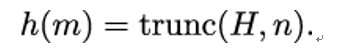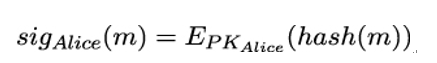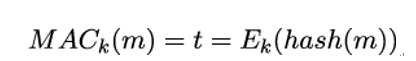10.5.12 The certificate_authorities extension
Finally, we turn to certificate authorities within TLS. TLS in itself places hardly any requirement on CAs, except that they should be able to issue X.509 certificates. However, Alice and Bob can use the certificate˙authorities extension to specify which certification authorities they support and which should be used by the receiving TLS party to select the appropriate certificates.
Client Bob sends the certificate˙authorities extension in his ClientHello message. Server Alice sends the certificate˙authorities extension in her CertificateRequest message. certificate˙authorities contains the CertificateAuthoritiesExtension data structure, as shown in Listing 10.8.
Listing 10.8: CertificateAuthoritiesExtension data structure
opaque DistinguishedName<1..2^16-1>;
struct {
DistinguishedName authorities<3..2^16-1>;
} CertificateAuthoritiesExtension;
In CertificateAuthoritiesExtension, field authorities holds a list of the distinguished names of suitable CAs. The CA names are represented in the DER-encoded format. The authorities variable also contains the name of the trust anchor or the subordinate CA. As a result, server Alice and client Bob can use the certificate˙authorities extension to specify the known trust anchors as well as the preferred authorization space.
10.6 Summary
In this chapter, we have discussed digital certificates as a means to provide authenticity for public keys, and the bodies that issue certificates, Certification Authorities (CAs). In particular, we looked at the minimum set of data that needs to be presented within a certificate, and the optional parts of a certificate.
Regarding CAs, we discussed their tasks and the processes for obtaining and validating certificates. We have also seen how CAs fit into the larger structure needed to manage public keys, the Public-Key Infrastructure (PKI).
After these more general considerations, we looked in detail at how digital certificates are handled within the TLS 1.3 handshake protocol.
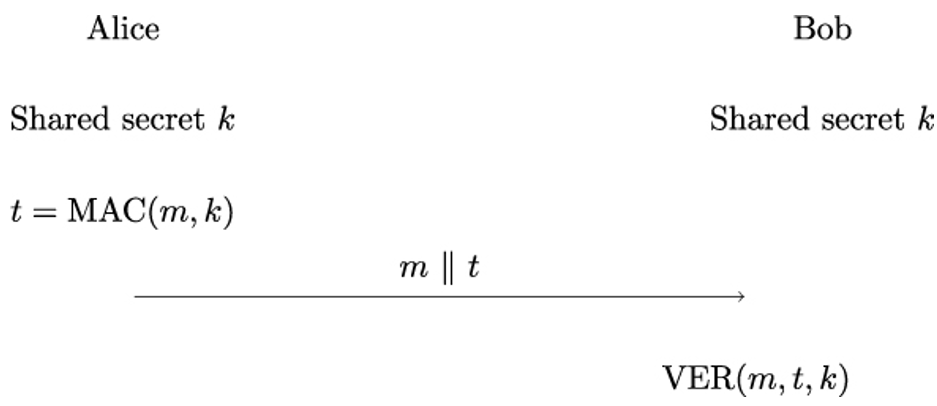
The next chapter will be more technical again, as it discusses hash functions and message authentication codes. Apart from digital signatures (which also use hash functions), they are the main cryptographic mechanisms for providing authenticity to handshake messages.